


新智元报道
编辑:定慧 Aeneas
【新智元导读】大模型越来越大,推理部署却举步维艰?就在刚刚,华为诺亚提出的Pangu Light框架,一举打破了「剪枝即降智」魔咒,揭示出LLM瘦身的新路径。毫无疑问,算法创新与国产平台的结合,还将爆发出无法想象的巨大潜力!
LLM发展到今天,下一步该往哪个方向探索?
显然,如今最明显的一个问题就是,大模型的参数规模还是太大了——DeepSeek-V3的参数为671B,Llama 3.1系列最大为405B,GPT-4o为200B,Claude 3.5 Sonnet为175B。
参数规模在不断增长,高昂的计算成本和推理延迟,该怎么破?
显然,无论推理还是部署,离开了老黄的「卡」,都将寸步难行。
假设真到了这一天,我们将不得不面临这一窘境时,不打无准备之仗,就是最好的策略。
这里,就引出了一个关键问题——如何将算法创新,与国产AI计算平台相结合。
具体来说,就是需要在保持模型性能的同时,实现高效的压缩与加速。
「裁员裁到大动脉?」
华为破悉关键
解决这个问题的关键之一,就是结构化剪枝技术。
顾名思义,这种「激进」的压缩技术,正是通过整个移除模型中的冗余组件(如注意力头等)来实现的。
结构化剪枝更适合硬件加速,因为它保持了模型的结构规则性。
然而只是简单粗暴的剪枝,却往往会遭遇滑铁卢,引发大问题。
实践表明,当尝试对模型的宽度(网络通道数)、深度(层数)等多个维度同时进行激进压缩时,模型性能会断崖式下跌——毕竟,大模型对于人类还是个黑盒:
激进的剪枝操作会严重扰乱模型原有的参数分布平衡和精心学习到的信息流动路径,使得剪枝后的模型结构失稳,性能大打折扣,甚至难以通过后续微调恢复。
打个不恰当的比方,这就好像是裁员裁到了大动脉,或者删除了看似不重要但起决定性作用的组件。
好在,面对这一难题,来自华为诺亚方舟实验室的研究者们,直接洞察到了问题的核心——
在剪枝之后,必须对模型的剩余参数进行精心的重新初始化与调整!
由此,他们推出了基于昇腾NPU的结构化剪枝与优化框架——Pangu Light。
通过创新性地引入了一系列权重调整与重置技术,最终,他们成功填补了当前方法在剪枝后模型稳定与性能恢复机制上的关键空白。
Pangu Light的核心技术包括:
-
旨在优化深度剪枝的跨层注意力剪枝(CLAP)
-
针对宽度剪枝的稳定化LayerNorm剪枝(SLNP)
-
为盘古模型「三明治」架构量身定制的Post-RMSNorm融合优化策略,并针对昇腾硬件平台进行了定制架构优化。
旨在优化深度剪枝的跨层注意力剪枝(CLAP)
针对宽度剪枝的稳定化LayerNorm剪枝(SLNP)
为盘古模型「三明治」架构量身定制的Post-RMSNorm融合优化策略,并针对昇腾硬件平台进行了定制架构优化。
实验结果表明,Pangu Light在压缩率和推理速度方面取得了显著提升。
并且,相较于一些已有的剪枝框架(如NVIDIA Minitron/PUZZLE的部分策略),Pangu Light展现出更优的效果。
剪枝后的Pangu系列模型在多项基准测试中,精度–效率曲线都超越了业界领先的LLM(如Qwen3系列)。
结构化剪枝的「梦魇」:
为何模型越剪越「伤」?
大模型结构化剪枝的初衷,当然是美好的——通过移除不重要的参数或结构单元,实现「瘦身健体」。
然而,当剪枝的「手术刀」同时伸向模型的深度、宽度、注意力机制乃至前馈网络(FFN)时,一场潜在的「噩梦」便可能开始。
传统的剪枝方法大多依赖于某种重要性评分机制来决定「去留」,例如神经元的激活值大小、权重的L2范数等。
仅仅移除「看起来不重要」的部分,会像抽掉积木塔的底层积木一样,导致整个模型的参数分布发生剧烈改变。
原本精心训练得到的权重,在移除了大量与之配合的「同事」后,其功能和意义可能已面目全非。
激活值的统计特性发生偏移,信息流在残缺的网络中传递受阻,最终导致剪枝后的模型性能大幅下降,陷入「一剪就坏,坏了难修」的困境,即便投入大量资源进行后续微调,也常常收效甚微。
正是因为洞察到这一「剪枝后稳定性」的核心症结,Pangu Light框架祭出了两大「杀手锏」——跨层注意力剪枝(CLAP)和稳定化LayerNorm剪枝(SLNP)。
这两大技术,正是为了从根本上解决剪枝带来的模型失稳问题。
Pangu Light核心技术解析:
稳定胜于一切
Pangu Light的成功,关键在于其独特的「剪枝」后「修复与重建」哲学,即通过精密的参数重置与结构调整,确保模型在「瘦身」后依然「筋骨强健」。
跨层注意力剪枝(CLAP):层剪枝后的「智慧缝合」
当整个网络层被移除(深度剪枝)时,其承载的注意力计算单元通常被完全丢弃,这对模型的信息处理能力无疑是巨大打击。
传统的逐层独立剪枝未能充分利用被剪层的信息,相比之下,Pangu Light的CLAP技术却展现了一种更为精妙的「跨层智慧」。
在研究者看来,即便一个层被判定为可剪枝,其内部的某些注意力头(特别是KV group)可能依然承载着不可或缺的关键信息。
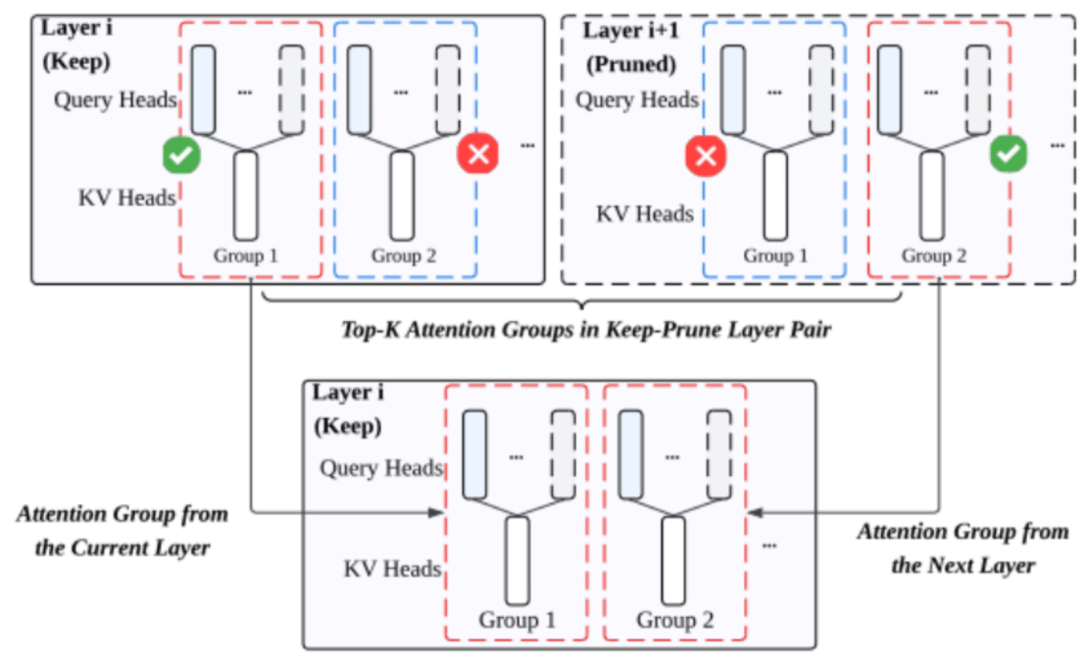
因此,在剪去第l+1层时,CLAP并不会将其注意力机制完全抛弃,而是会联合评估第l层和第l+1层中所有KV group的重要性。
这种重要性基于其内部尚存的Query Head的初始重要性:
式中,

表示query head的初始重要性,
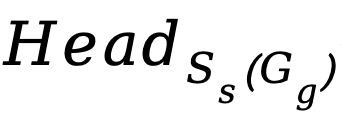
表示一个KV group中保留的query head的集合,
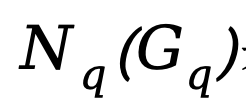
表示KV group中保留的query的数量。
从这两层的所有KV group中,选取Top-K最重要的KV group,将其参数「移植」并整合到第l层。
这相当于将被剪层l+1的「精华」注意力权重,巧妙地「缝合」并重新初始化到保留层l的注意力机制中,实现了信息的跨层保留与结构功能的有效重组。
稳定化LayerNorm剪枝(SLNP):宽度剪枝后的「定海神针」
当网络宽度被压缩,即隐藏层通道被剪枝时,RMSNorm(或LayerNorm)层中的可学习仿射参数γ的维度也随之减少。
这一变化看似简单,实则极易引发「蝴蝶效应」:γ的L2范数(即其整体尺度)可能发生剧变,进而显著改变RMSNorm层的输出激活值的统计分布。
这种分布的漂移会逐层传递、放大,最终导致整个网络内部的激活状态极不稳定,严重阻碍剪枝后模型的收敛和性能恢复。
怎么办?为此,研究者们提出了SLNP技术,这套权重重置方案有效地直接针对了这一问题。
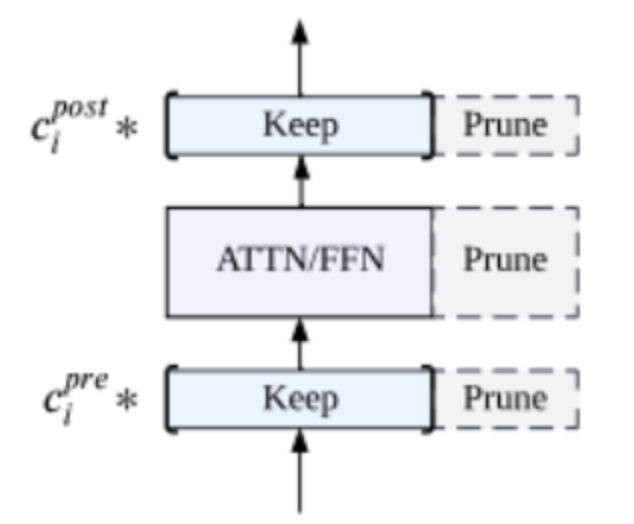
他们发现,通过精确调控剪枝后RMSNorm层γ参数的L2范数,使其恢复到剪枝前的水平,对于维持模型稳定性至关重要。
具体而言,对于每个被剪枝的RMSNorm层l,SLNP会计算一个重初始化标量:
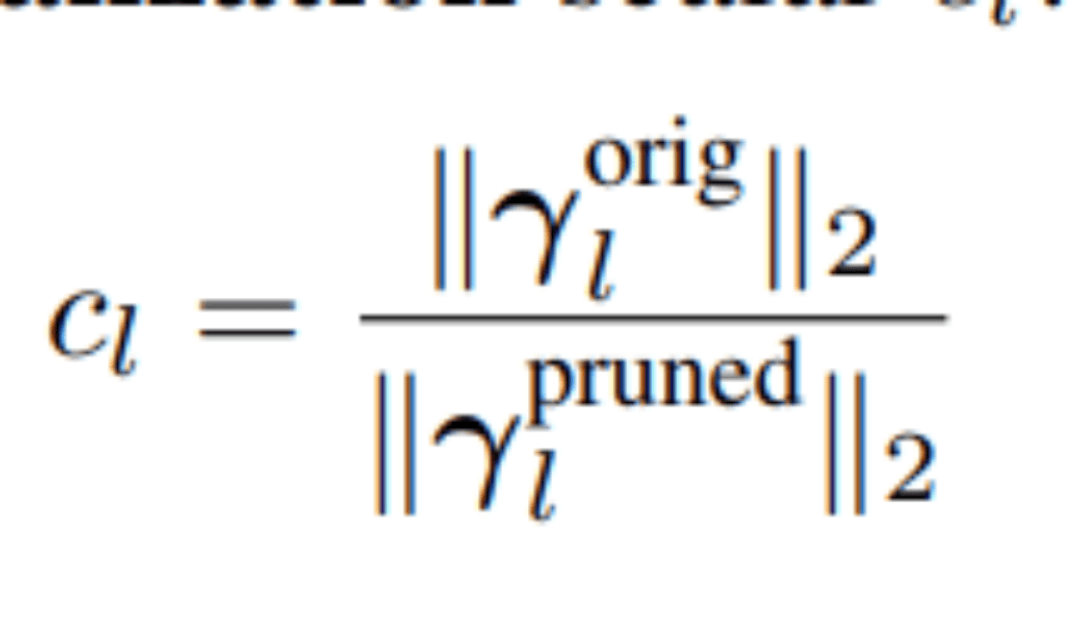
(分子和分母分别为剪枝前后参数γ的L2范数)。然后,用这个标量重新缩放剪枝后的γ参数。
这一简单的重初始化步骤,却如「定海神针」一般有效。
它校正了输出尺度,显著提升了模型在剪枝后的稳定性与后续微调的收敛性。
Post-RMSNorm融合优化策略
另外,Pangu系列大模型还采用了一种独特的「三明治」归一化(Depth-Scaled Sandwich-Norm, DSSN)架构,即在每个Transformer块的注意力模块和FFN模块之后都额外增加了一个RMSNorm层。
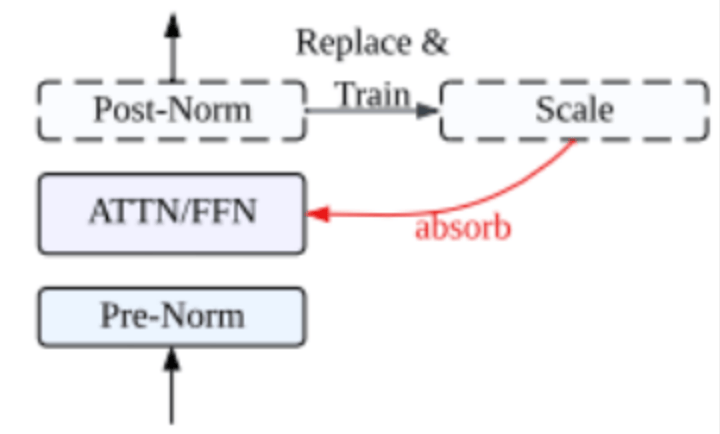
这一设计极大地增强了大规模模型训练的稳定性,甚至实现了「零训练毛刺(zero loss spikes)」的佳绩。
然而,这种归一化也无可避免地带来了额外的推理计算开销。
标准的RMSNorm计算公式如下:
RMSNorm会实时计算每一个输入token的统计值,这极大影响了模型的推理效率。
为此,针对这种额外引入的Post-RMSNorm,研究者通过少量校准集求取该统计值的均值,并将该均值替换RMSNorm的实时计算,其表达式如下:
替换后,归一化层的计算公式表示如下:
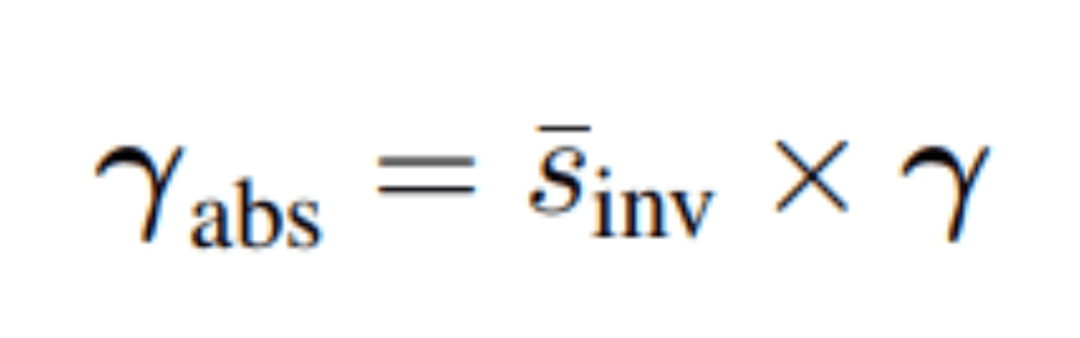
这一变换有效地将Post-RMSNorm层替换为一个常数的逐通道缩放操作。
同时,这一缩放操作可以将归一化层的参数融入线性投影层的权重矩阵中,消除了PostNorm额外引入的参数。
实验验证
为了验证Pangu Light框架的实际效果,研究团队以Pangu 38B模型为基准,在华为昇腾NPUAI处理器上进行了一系列详尽的模型压缩实验。
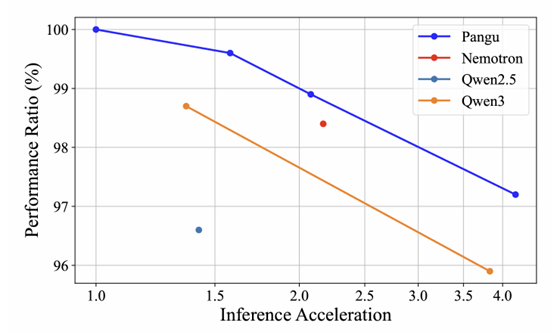
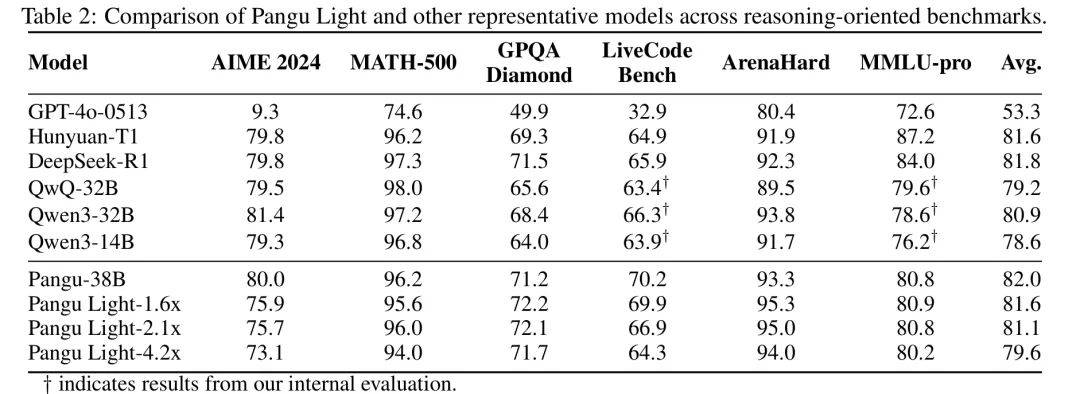
从实验结果可以看出,Pangu Light在不同的压缩比例下,均能非常有效地保持模型的精度。
与参数量相近的业界知名模型Qwen3-32B相比,Pangu Light压缩后的模型在多项任务上展现出更强的竞争力,平均精度更优。
在同样加速2.1x的情况下,Pangu Light保留了高达98.9%的原始模型推理能能力,超越英伟达提出的PUZZLE压缩方案(保持98.4%的精度)。
在推理吞吐量方面,研究团队在昇腾NPU的配置下进行了测试。
结果显示,Pangu Light剪枝后的模型在昇腾硬件平台上表现出卓越的亲和力。
以32B规模的模型为例,Pangu Light-32B的吞吐量相较于Qwen3-32B提升了接近16.2%(2585 vs 2225 tokens/s)。
这就充分证明了其软硬协同优化的有效性,实现了模型性能与推理速度的更优平衡。
消融实验
为了进一步验证Pangu Light中各项创新技术的独立贡献,研究团队还精心设计了消融实验。
在一项基于14B规模模型的少量数据微调评测中,对比仅基于激活值进行剪枝的策略(NVIDIA Minitron方案的),同时采用CLAP和SLNP这两种「宽深调整」(实为权重重置与结构调整)技术的Pangu Light模型,在平均精度上实现了高达3.6个百分点的提升。
这一显著差距,充分证明了在剪枝之后进行系统性的参数调整与重置的极端重要性,以及Pangu Light所提方法的优越性。
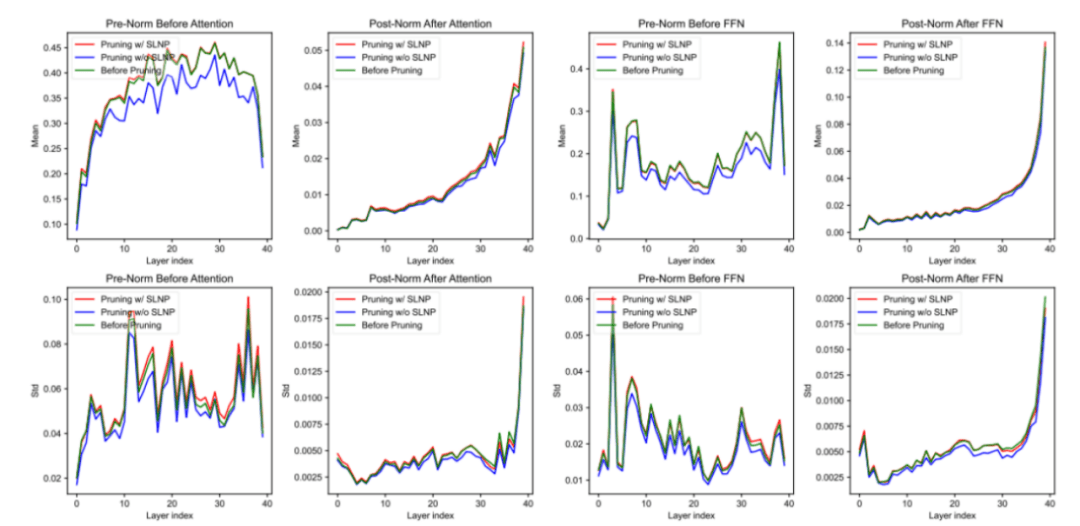
为了深入探究Pangu Light剪枝方法学对模型内部参数的影响,特别是其核心的SLNP权重重置策略如何维持稳定性,研究者们还细致分析了模型归一化层的仿射缩放参数γ在剪枝前后的分布变化。
分析着重聚焦于那些在剪枝后被保留下来的通道和层所对应的γ参数。
结果清晰地显示,在应用了Pangu Light的剪枝和SLNP重置策略后,这些被保留的γ参数的均值和标准差在每一层都与剪枝前保持了高度的一致性。
这一现象有力地说明,Pangu Light的剪枝与权重重置方法能够有效维持这些关键缩放参数学习到的统计特性,避免了剧烈的分布漂移。
这种参数层面的稳定性,是剪枝后模型整体鲁棒性和行为可预测性的重要基石。
昇腾赋能,华为引领AI普惠之路
可见Pangu Light框架的提出,无疑为LLM的高效部署领域注入了强劲的新动能。
它结合了系统性的结构化剪枝与创新性的「剪枝后权重重置与结构调整」理念,尤其强调了在激进剪枝后对模型进行「再稳定化」的核心步骤。
由此,这个框架就成功破解了长期困扰业界的「一剪就坏」难题。
甚至,在昇腾AI处理器的强大算力支持下,Pangu Light不仅实现了超高的模型压缩率和推理加速,更难能可贵地保持了极具竞争力的模型精度,展现了卓越的「精度–效率」均衡艺术。
可以说,这项由华为诺亚方舟实验室主导的研究成果,是软硬件协同设计(「软硬协同」)理念的又一次成功实践,充分彰显了算法创新与国产AI计算平台(昇腾)深度融合所能爆发出的巨大潜力。
从此,不仅Pangu系列大模型有了强大的「瘦身」与加速工具,业界更是有了一条极有前途的路径——
在保证高性能前提下,大模型应用的门槛,还将继续大幅降低!
参考资料:
https://arxiv.org/abs/2505.20155
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






